Google Book Search: The Good, the Bad, & the Ugly
- By Dian Schaffhauser
- 01/01/08
 Yes, Google is opening up whole new worlds for internet surfers
and researchers everywhere-even before the model is ready.
Yes, Google is opening up whole new worlds for internet surfers
and researchers everywhere-even before the model is ready.
FORGET EVERYTHING YOU BELIEVE about Google's book digitization
project. Once you get past the freakishly high numbers bandied about, the two-dozen-plus distinguished
institutions that have signed on, the legal paranoia and the ultra-ultra-secret processes and technologies
involved-you'll find that Book Search (from the fifth most valuable company in America) is simply another
high-cost effort that is simultaneously visionary and crude. It doesn't even have to succeed in order to
impact the transformation of scholarship activities.
Here's the magic: Type "sonoma" and "mission" into books.google.com and choose "Full view" to eliminate
those books that haven't granted permission to be fully displayed or that are still in copyright because
they were published post-1923. About 550 titles show up, almost all of which you can view in text format
or as a PDF file. Perhaps the oldest reference that will appear is a volume titled An Overland Journey Round
the World During the Years 1841 and 1842 by Sir George Simpson, governor-in-chief of The Hudson's Bay
Company's territories. Google digitized the 1847 volume from the collection of the New York Public
Library, as the bar code on the cover shows (along with a small portion of what looks to be a human arm,
probably belonging to the person scanning that particular title).
LISTEN IN
Download our podcast interview with Robin Chandler, former director of data acquisitions for UC's California Digital Library.
As a reader, you might consider the
discovery of this long-lost tome a
modern-day miracle, akin to stumbling
on the bones of a previously unknown
dinosaur while digging in your garden.
And even though you never have to
leave your keyboard to read the contents,
you could click a link on the page,
enter your ZIP code, and find the nearest
library that has the book in its collection,
in case you're the kind of person
who likes to touch actual pages and take
in the perfume of old book stock.
Somehow (although the details are
mostly sketchy to those outside the
company), thousands of books are
working their way through the project
every business day to join the millions
of other publications already included
in Book Search. But let's take a look at
how Google is working with one of
its partners-the University of California system-to keep the process
humming along.
Google Book Search: Typical User View
GOOGLE BOOK SEARCH, which is still in beta after several years of
testing, offers the ubiquitous Google search box on its home page. It also has categories of
books as well as book cover images that refresh every time the home page is refreshed.
Once the user searches for a book and pulls up its record, one of two screens appears,
depending on whether the book is under copyright or not. Copyrighted books display a limited
number of pages ("snippets"), including the cover and back cover, the table of contents,
the index, and some content pages. For Steven Levitt and Stephen Dubner's Freakonomics (William Morrow, 2006), for instance, Google shares 29 pages of the 256-page tome. But
users can pull up a full-screen view of any of the 29 pages, write a review of the book, add it
to their online libraries, view the table of contents and some popular passages, search the
contents (only page numbers may show up), click through to other editions of the same
work, click to sources where you can buy the book or find it in a library (a link that connects
you to WorldCat), and read paid sponsor links.
For books no longer under copyright (current criteria: those works published earlier
than 1923, such as an edition of Adam Smith's The Wealth of Nations published in 1895
[T. Nelson and Sons], or books that the publishers have granted full viewing rights to), the
same features exist, though not all include paid sponsor links. For some books, users can
view a PDF edition (with download size shown) or view a plain-text version of each page.
When read in full-text mode, the non-copyrighted books allow Book Search users to view a
single page or facing pages, simultaneously, and make an annotation to be included in Google Blogger or Google Notebook. Perhaps more
helpfully, users can copy a link provided by Google, and forward it to others. When used correctly,
that function can take another reader to the same page and a specific clip captured by
the original reader with a dashed line marking off the content. Some books even include a
Google Maps mashup showing "Places mentioned in this book."
Quality vs. Quantity?
The UC system consists of more than 100
libraries spread across 10 campuses
around the state, containing more than 34
million volumes, which inhabit 3.6 million
square feet of library building space.
According to the UC-Berkeley library
website, in North
America the holdings of the state university
system are surpassed in scale only by
the Library of Congress. Just under a
third of the collection is housed in two
regional facilities, one located on the
campus of UCLA serving the southern
campuses; and the
other in an industrial area of Richmond
outside of San Francisco, serving the
northern schools. This makes the digital effort easier,
since neither Google nor the UC librarians
need to scurry from campus to campus
to obtain books to scan. Yet it also
suggests the possibility that Book Search
is actually a project all about numbers
over quality-an implication that neither
UC nor Google denies.
In fact, when UC signed its contract
with Google in July 2006, UC agreed to
provide no less than 2.5 million volumes
to the digitization effort over the course of
the agreement's six-year period. That's
just under 420,000 books a year, or less
than a tenth of the annual circulation of
materials throughout the UC library system,
which circulated 4.7 million items in
the 2005-2006 academic year. According
to the contract, after an initial ramp-up
of a couple of months of delivering 600
books per day, UC was obligated to crank
up delivery to 3,000 per day. And that,
says Robin Chandler, former director of
data acquisitions for UC's California Digital
Library (CDL), is exactly what UC's
goal has been. (This month, Chandler is
moving to a digital library position at the
University of California-San Diego.)
Chandler, who held the CDL role for
seven years, worked with a multitude of
libraries inside and outside the UC system,
to help guide their digitization
efforts. That includes Calisphere, a
public gateway to 150,000 digitized
items (including diaries, photographs,
political cartoons, and other cultural
artifacts representing the history and
culture of California), as well as the
Online Archive of California, which brings together historical
materials from a number of California
institutions including museums,
historical societies, and archives.
Do Authors Want to Be Digitized?
 GREG SCHULZ, FOUNDER OF AND SENIOR ANALYST for The StorageIO Group-and interviewed for this article-is also the author of the book, Resilient Storage Networks (Digital Press, 2004). It doesn't bother him in the least that Google
Book Search might scan his entire book and make pieces of it available.
GREG SCHULZ, FOUNDER OF AND SENIOR ANALYST for The StorageIO Group-and interviewed for this article-is also the author of the book, Resilient Storage Networks (Digital Press, 2004). It doesn't bother him in the least that Google
Book Search might scan his entire book and make pieces of it available.
"I'm fine with that," he declares. "If it allows my work to be more widely
known so that people buy the book or engage in other related services, I'm
all for it. I'll gladly give up some book sales if it leads to something else."
The sticking point? When Google or other book-search projects "start leveraging
the work, or doing things with it. Then it gets into another dimension," says Schulz, pointing
to the recent Writers Guild strike. "At the center of that is: How do new media efforts affect royalties?
What happens?" In other words, a green light for now doesn't mean a green light forever.
"I've worked on a lot of projects that
have had complex partnership [components],"
she says. "So [CDL] asked me to
work on the mass digitization activities."
That mandate surfaced two years ago,
first with the Open Content Alliance, a nonprofit effort that's part of the Internet
Archive project; then
with Microsoft as
part of its Windows Live Book Search;
and most recently with Google Book
Search. Acting as the program liaison for
those projects, she says, consumed about
75 to 80 percent of her time at CDL.
How does UC deliver 3,000 books a
day to Google? It isn't by being overly
selective. And it doesn't involve rare
materials that aren't part of the circulating
collection. "All of the libraries are
talking about that, in the sense of what
might be the most interesting materials
to scan," says Chandler. "But I'll be
very frank: There's a real balance point
between volume and selection, especially
when looking at these numbers. UC
is trying to meet the needs of the contract
it's signed."
Ultimately, the library has to perform
bulk selection, "which means choosing
both in-copyright and out-of-copyright,"
she says. "So without having to worry
about publication dates and such, you're
literally able to clear shelves."

KIRTAS TECHNOLOGIES' APT BookScan 2400 Gold robotic
scanner is capable of digitizing 1,344 books a week.
The issue of copyright was something
Google stumbled over early in its founding
of Book Search (previously dubbed
the Google Print Library Project, even
though users apparently weren't allowed
to print anything). After a brief hiatus, the
site was modified to reflect the more
copyright-holder-friendly practices of
competitive offerings from Microsoft and
the Open Content Alliance. It comes
down to this: Full text is available for out-of-copyright materials and for copyrighted
books from publishers who allow it;
limited content is displayed for newer
books. Lawsuits are still pending.
As Chandler describes it, a staff member
removes the entire shelf of books,
places the books on a book truck, then
moves on to the next shelf, "until, essentially,
the quota for a day is reached. Then
they're checked out." Although
Google doesn't have a UC library
card per se, the books heading off
for scanning go through the same
checkout process as any volume
leaving the facility. Their bar codes
are read and a manifest is compiled,
"to be able to account for a day's
shipment," she explains. "It's very
important not to lose a book anywhere
along the way."
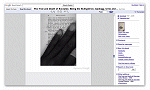
GOOGLE'S SCAN OF this page from an 1888 edition of Plato's The Trial and Death of Socrates suggests that humans-and human error-are a large part of the Book Search digitization process.
Behind Closed Doors…
Once the volumes move through the
checkout, they're purported to be
loaded onto another truck-one
which takes the volumes to an
undisclosed location where the
Google scanning facility is set up.
At that point, operations become a
black box. (It's possible that the
scanning occurs at the regional UC
facilities themselves, but UC
staffers aren't talking. Citing proprietary
concerns, Chandler declines to
answer questions about scanning operations,
and Dan Clancy-engineering
director for Google, in charge of leading
the Book Search team-is just as cagey.)
"When it first started, the technical
challenge was simply building a scanning
device that worked," Clancy says. "The
next technical challenge was being able to
run this scanning process at scale. We
would have been quite happy to use commercial
scanning technologies if they
were adequate to scale to this. We only
built our own scanning process because
that was the way to make this project
achievable for Google."
Book Search Today: A Researcher's View
SUSAN FARMA IS WORKING ON her master of arts in humanities at California State
University-Dominguez Hills. Because she's working full-time as an application manager for
the Los Angeles Philharmonic, Farma was thrilled when she learned about Google Book
Search. "Anything that saved time I considered a boon," she says. "But it has not provided the
help in research that I hoped." Her complaint: "I find it has severe limitations. For instance, if
the book is not in the public domain, the snippet view only shows you the word you searched
for and a few words around that word. There is no way to tell from the half a sentence that
[Google shows you], whether buying or borrowing the book in question would be able to
advance your thesis." In addition, says Farma, "books in the public domain online are few and
far between yet, and most of them are extremely old. [Book Search] works great for classics
in, say, literature, but not for individual subjects that you may be interested in researching."
Let's look at what Google may have
rejected as inadequate to do the job: The
APT BookScan 2400 Gold, the fastest
commercial offering from digitization
vendor Kirtas Technologies, scans books at a rate of
2,400 pages per hour. The product costs
between $100,000 and $175,000 and
includes two cameras, each pointing
downward at a 45-degree angle. In a
video on the company's website, a worker
is shown placing a book in a cradle and
making adjustments for its size. As both
pages are whipped through the scanning
simultaneously, a robotic arm that looks
like a waffle iron adheres to a page and
flips it for the next photo shoot to occur.
The question is: Is that fast enough to
keep up with Google's demands? At an
average size of 300 pages per book (a
count cited by UC's Chandler), Kirtas
equipment is capable of scanning eight
books an hour or 64 books in an eighthour
workshift. If scanning operations
were running around the clock and staffers never took breaks, called in
sick, or experienced equipment outages,
the tally would reach 1,344 books a
week per machine. Keeping up the pace
of those 15,000 books a week fed by UC
would require 12 of the Golds. Yet
apparently, Google is using something
else it considers superior.
When a Text Isn't Text
THE PAGES OF TEXT SHOWN through Book Search are actually images, not text. Although as
part of Google's digitizing process a conversion takes place to turn a scanned page into text,
the publicly offered results are less stellar than those made possible by the better-known OCR
applications such as Abbyy FineReader, which is used by compression software
provider LuraTech as part of its PDF conversion solution.
Frequently, an out-of-copyright book in Google will include a "View plain text" function,
but the user will be shown a page displaying only "No text" at the top-meaning that
Google was unable to convert that particular page into plain text. And if a user's keyword
search turns up such a page, Book Search still succeeds in locating and highlighting the
search terms, even if it can't seem to display the page in plain-text form. It's almost as if
two separate optical character recognition systems are in play: one for the search engine,
and another for converting scanned pages into plain text. This inconsistency may not trouble
most readers; but those who are print-disabled and need to use a screen reader or
convert the text to a speech reader, say otherwise.
Susan Gerhart holds a doctorate in computer science and has worked in research and management
in software engineering and technology transfer at Duke University (NC), NASA, the
National Science Foundation, USC's Information Sciences Institute, and Embry-Riddle Aeronautical
University (FL). Gerhart is also legally blind. As she points out in her blog, As Your
World Changes, her experiments in using Book Search
have turned up this anomaly, for settings that turned images off in her browser. "I got a snippet
of page text, a big empty block of missing image, and various book metadata, including where
to buy or borrow," she says. When she tried turning images on, "Ouch, was it bright," she recalls.
She writes: "There's nothing in, around, or any way out of the image into screen readable
mode. The image might as well have been a lake, a building, or porn for all the information
I could glean from it. I wondered why the omnipotent Google toolbar, gathering data about
my searches, and offering me various extra search information, could not also be the reader."
Gerhart is doubtless not alone in her frustration.
Linda Becker, the VP of sales and marketing
for Kirtas, doesn't believe that
Google has somehow created a faster digitization
process. "I do know what they're
doing, and I can't comment on it," she
says. "But what I can say is this: They're
not scanning faster, they're not digitizing
faster, and they don't have the quality
controls that the user deserves."
She may be right: In an ongoing online
debate about whether Google is using
robotic machinery or human beings to
flip the pages, bloggers have poked fun
at the search giant's quality control
methods (or lack of them) by posting
screenshots that reveal hands, fingers,
and arms in Book Search results. Becker
suggests that those screenshots may not
be anomalies. "If you go into Google
[Book Search] and look at any book,
you'll be able to see by the number of
body parts and fingerprints that [the
pages] are being turned manually."
Although Clancy won't describe the
actual process or equipment being used
for Book Search, he does point out that
one of the reasons he was recruited by
Google (from a lengthy career at
NASA) was because, "One, I had a
strong AI [artificial intelligence] background.
Two, I had a lot of experience
dealing with complex systems that had
lots of mechanical components along
with software components. And three, I
had the ability to do things to scale-an
important part of the Books project.
There are a lot of software complexities
[in that]," he concedes, "but also a lot of
people complexities."
Parlez Vous… Telugu?
BOOK DIGITIZATION PROJECTS aren't new. Carnegie Mellon University's (PA) Universal Digital
Library (UDL), which has been in the works since 2001, recently
announced that it had digitized 1.5 million books, including 971,594 titles in Chinese, 49,695
in Telugu, 39,265 in Arabic, and 20,931 in Kannada (Telugu and Kannada are both languages
of southern India), among other languages. That emphasis on multiple languages sets UDL
apart from other book digitizing efforts. The volumes are being scanned by universities and
organizations in multiple countries-the US, China, Egypt, and India-and are made available
free in three formats: HTML, TIFF, and DjVu (a PDF alternative). Although the details may differ,
the goal of the initiative sounds familiar to those who follow such matters: "to create a universal
library which will foster creativity and free access to all human knowledge."
There's more than that at stake, insists
Kirtas' Becker. The actual scanning
process isn't what's important in these
projects, she points out. "People get confused
between digitizing and scanning.
When you scan a book, you get what you
get. Digitizing is what Kirtas does. Once
we scan a book, we take it through a digitizing
process." That encompasses multiple
steps, she maintains: segmenting the
book (converting pages to black and
white from color, if that's how they started
out), performing background cleanup,
converting type size (such
as for applications for the visually
impaired), changing the book size for
printing purposes, and moving the digitized
content into other file formats such
as for online reading or PDF viewing.
"Right now," says Becker, "scanning is
irrelevant. What is relevant is this: How
do you create the highest quality digital
file with the smallest file size that's repurposable
so that you can extend the life of
it?" She believes that's what the Google
Book Search project is missing: a focus
on quality. "If you were to go to the
Google site, you'd see that one out of
every five pages is either missing, or has
fingers in it, or is cut off, or is blurry."
Still, avoiding at all costs the odd missing
page or disembodied digit may not be
a driving force behind Book Search right
now. UC's Chandler notes the qualitative
differences between the output produced
by the three mass digitization efforts she
was involved in at CDL. "The actual presentation
of the book is quite different. If
you look at what Google does, it's really
a bitonal representation. It's as if the book
were brand new, which is just to say that
the page is white [and] the ink for the font
is black. Whereas if you look at the
Microsoft [Windows Live Book Search]
presentation, it's a color image, so you get
the sense of it as an artifact."
In point of fact, it's possible that a good
number of books submitted for scanning
are out-and-out rejected in the Google
process. According to UC's Southern
Regional Library Facility annual report, it had scanned 33,503 volumes for the
Open Content Alliance project in one
year. (Neither Google's nor Microsoft's
numbers were provided.) An additional
16,988 volumes pulled off the shelves for
scanning were rejected, mostly because
they had tight margins, large foldouts, or
brittle paper. For every two books successfully
scanned, another one was
rejected and added to a list tagged "With
the hope of going back." There's little
reason to believe that Google's success
rate is dramatically different.
Storing a World of Files
Google's Clancy says the current database
of books in Book Search contains
"millions and millions" of volumes.
That requires a lot of storage work, no
new challenge for Google.
Greg Schulz, founder and senior analyst
for The StorageIO Group, observes, "Knowing
Google, they're storing it the same way
they store all their other data: They're
using clustered nodes of processors
with drives in them-a Google storage
grid." The Google data center model,
which has been well documented and
marveled over, is to leverage commodity
servers (X86 and AMD) in volume.
These are servers, says Schulz, "that
you can buy very, very inexpensively,
and that give you a good balance of performance
and storage capacity for a low
cost." And when Schulz says volume, he
means tens-possibly hundreds-of
thousands of servers.
On top of that hardware runs Google
software: the Google File System, the
Google storage management tools, and
other layers-"for monitoring and making
sure the hardware is running efficiently,
that it's healthy, and that the
data is protected. That way, if a server
fails, the others can pick up the workload,"
Schulz says.
The actual data recorded by the
scanning process is probably maintained
in Bigtable, a distributed storage
system for structured data. As described
in a white paper published by Google
in 2006, "Bigtable is
designed to reliably scale to petabytes of
data and thousands of machines. Bigtable
has achieved several goals: wide applicability,
scalability, high performance,
and high availability." While the paper
doesn't mention Book Search by name, it
does state that Bigtable is used by more
than 60 Google products and projects.
Although the equipment and software
for Book Search has evolved to become a
string of proprietary systems, Clancy
insists that his company uses commercial
standards where they work. That includes
image compression standards like JPEG
(and its successor JPEG 2000), PNG,
TIFF, and PDF.
Processing Book Files
Image compression isn't a small issue in
mass digitization projects, says Mark
McKinney, VP of business development
for LuraTech, a
company that produces compression
software. Besides consuming storage,
the files developed out of scanned books
need to be delivered across the web with
no perceivable delays. LuraTech powers
the work done by the Open Content
Alliance, which applies the JPEG 2000
format to compression; JPEG 2000 is a
powerful long-term archival format that
reduces a large color file to about a hundredth
of its original size, says McKinney.
In that effort, he says, workers run
the process from digitization stations
called "Scribes" that take the picture
from a page, color-correct it, and then
"OCR" it (apply optical character
recognition) so it becomes searchable.
Once the operator has captured all the
individual pages, metadata is added to
the book through a user interface. But
the metadata-title, author, copyright,
description, etc.-isn't necessarily added
via human effort.
According to Brian Tingle, a technical
leader for the Digital Special Collections
(part of UC's CDL), much of the metadata
is already cataloged as part of the
online public access catalog (OPAC), known in the pre-digital era as the
card catalog. Tingle's team works
with a metadata object format, a standard
for encoding and transmission
of digital objects. "Those objects get
turned into those formats and that's
how we ingest them into our system,"
he explains. It's a different level of
metadata that enables the linking
together of objects, such as the pages
of a book.
The automation of data capture is
certainly something in which a former-
NASA AI expert like Google's Clancy
would excel. "If you look on our book reference
page, you'll find related works
identified; books with some relationship
to the book you're looking at," he points
out. "Or you'll find something we call
‘Popular Passages,' where we've extracted
passages that are seminal or popular
and mentioned in a number of different
books. We use that as a way to link some
of these books together." Achieving those
connections, he says, is a programming
job. "It may not be perfect, but this is 100
percent how we've done it. We don't have
people picking out related books; we use
lots of different signals. We just don't talk
about which signals we use."
Beyond Automation
Not surprisingly, when the wizard behind
the curtain is Google, the same kind of
secrecy applies to search. Where UC's
Tingle is highly forthcoming about the
search product his team has developed
at CDL-eXtensible Text Framework
(XTF), which is based on Lucene, an
Apache open source search engine-Google's Clancy
prefers to focus on search outcomes.
"We're all familiar with how search
works on the web," says Clancy. "You
type in a keyword phrase and suddenly it
seems to find just the document you
want; people create link structures that
relate two things together. Well, as soon
as you do that [with a book], you're giving
us more information about that book.
Eventually, you can imagine people linking
to books from their web pages and
other things. A book should be like the
web: People should link directly into the
book when it's relevant to them."
What form would that take for the person
doing the search? According to Clancy,
Google features to make book links
possible have just begun to surface. One
tool introduced (in the interface for books
that are under no copyright restrictions)
allows the reader to capture a section of a
full page and copy it as text or an image to
a Blogger page or
Notebook,
both Google services. "If there's a particular
quote you like, you can go ahead and
create a clipping of that quote, stick it on
your blog and say something like, ‘This is
where Abe Lincoln first asserted his
desire to free the slaves.'"
Eventually, he says, authors will be
able to represent "not just the conclusions
and assertions they're making, but also
the data upon which they base those
assertions." He describes somebody
reading David McCullough's 1776 (Simon & Schuster, 2005) being able to
click through to primary sources such as
George Washington's diary or the letters
written by John Adams. But, "Now, I've
gone beyond what Google is going to do,"
Clancy says. "As you open up all this content,
these are research challenges for
libraries, for the research communities,
and for Google to say: How does this
change scholarship?" Clancy envisions a
day when users of online catalogs such as
Melvyl (UC's OPAC)
can find the record of a book and immediately
link over to the content, whether
that material is hosted by Google, UC, or
some other institution with which the university
has affiliated itself.
Still, without the profit-driven motives
of a company such as Google (or
Microsoft, for that matter), UC would
never have had the funds to scan its materials
on such a broad scale, maintains
Chandler. "Strategically, it's really an
important opportunity to take advantage
of." Ultimately, she says, "We utilize the
environment in which our faculty and students
are working, and more and more
obviously, it's digital."
When it comes down to it, then, this
brave new world of book search probably
needs to be understood as Book Search
1.0. And maybe participants should not
get so hung up on quality that they
obstruct the flow of an astounding
amount of information. Right now, say
many, the conveyor belt is running and
the goal is to manage quantity, knowing
that with time the rest of what's important
will follow. Certainly, there's little
doubt that in five years or so, Book
Search as defined by Google will be very
different. The lawsuits will have been
resolved, the copyright issues sorted out,
the standards settled, the technologies
more broadly available, the integration
more transparent.
"One thing we've learned," says Clancy:
"We don't try to anticipate how people
will make use of something. We're just at
beginning of the marathon."
::WEBEXTRAS ::
The CIC's Richard Ekman weighs
in on the Google Book Search controversy:
www.campustechnology.com/articles/41199.
Dian Schaffhauser covers technology
and business for various print and
online publications.