MIT Report: Most Organizations See No Business Return on Gen AI Investments
A recent report out of the MIT Media Lab found that despite $30-40 billion in enterprise spending on generative AI, 95% of organizations are seeing no business return.
The authors of the July 2025 report, titled "The GenAI Divide: State of AI in Business 2025," wrote: "The outcomes are so starkly divided across both buyers (enterprises, mid-market, SMBs) and builders (startups, vendors, consultancies) that we call it the Gen AI Divide," noting that "Just 5% of integrated AI pilots are extracting millions in value, while the vast majority remain stuck with no measurable P&L impact."
What the 'Gen AI Divide' Means
The divide is defined by high adoption but low transformation. The report said only two industries show clear signs of structural disruption, while seven others show "widespread experimentation without transformation.
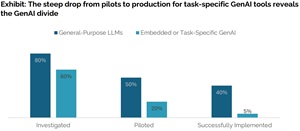 [Click on image for larger view.] The GenAI Divide (source: MIT Media Lab).
[Click on image for larger view.] The GenAI Divide (source: MIT Media Lab).
It backed this with an AI Market Disruption Index and included an interview quote from a mid-market manufacturing COO: "The hype on LinkedIn says everything has changed, but in our operations, nothing fundamental has shifted. We're processing some contracts faster, but that's all that has changed."
Pilot-to-Production: Where Most Efforts Stall
The sharpest evidence of the divide is deployment: "only 5% of custom enterprise AI tools reach production." The report characterized this as a 95% failure rate for enterprise AI solutions and attributes it to brittle workflows, weak contextual learning, and misalignment with day-to-day operations. It also recorded user skepticism about vendor offerings: "We've seen dozens of demos this year. Maybe one or two are genuinely useful. The rest are wrappers or science projects."
Enterprises run the most pilots but convert the fewest; mid-market organizations move faster from pilot to full implementation (~90 days) than large enterprises (nine months or longer).
Adoption Numbers vs. Business Impact
General-purpose tools are widely explored, but impact is limited: "Over 80% of organizations have explored or piloted [ChatGPT/Copilot], and nearly 40% report deployment," yet these mainly improve individual productivity, not P&L performance. Meanwhile, 60% of organizations evaluated enterprise-grade systems, "but only 20% reached pilot stage and just 5% reached production."
The Root Cause: The Learning Gap
The report's central explanation is that the core barrier is learning rather than infrastructure, regulation, or talent: "Most GenAI systems do not retain feedback, adapt to context, or improve over time."
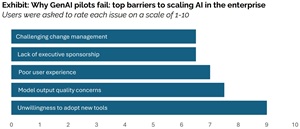 [Click on image for larger view.] Why AI Projects Fail (source: MIT Media Labs).
[Click on image for larger view.] Why AI Projects Fail (source: MIT Media Labs).
Users often prefer consumer LLM interfaces for drafts, but reject them for mission-critical work due to lack of memory and persistence. One interviewee explained: "It's excellent for brainstorming and first drafts, but it doesn't retain knowledge of client preferences or learn from previous edits. It repeats the same mistakes and requires extensive context input for each session. For high-stakes work, I need a system that accumulates knowledge and improves over time."
The report summarized this gap succinctly: "ChatGPT's very limitations reveal the core issue behind the Gen AI Divide: it forgets context, doesn't learn, and can't evolve." For complex, longer-running tasks, humans remain the strong preference.
Shadow AI: Workers Cross the Divide Informally
While official programs lag, a "shadow AI economy" has emerged: "only 40% of companies say they purchased an official LLM subscription," yet workers from over 90% of the companies reported regular use of personal AI tools for work. This pattern shows individuals can cross the divide with flexible tools even when enterprise initiatives stall.
Why This Matters
For teams tasked with operationalizing AI in cloud environments, the report indicated that the bottleneck lies in systems that can learn, remember, and integrate with workflow systems. The "divide" is not about model IQ or raw infrastructure capacity, but about embedding adaptive behavior into the application layer and process orchestration.
Methodology
The report is based on a multi-method research design conducted between January and June 2025. Researchers performed a systematic review of more than 300 publicly disclosed AI initiatives, held 52 structured interviews with representatives from organizations across industries, and gathered 153 survey responses from senior leaders at four major conferences. Company-specific data and quotations were anonymized to comply with disclosure policies.
The report is available at the nandapapers GitHub repo here.
About the Author
David Ramel is an editor and writer at Converge 360.